
今天要分享的是Hahow爬蟲-學會如何爬取Ajax網頁!
Ajax網頁流程如下:
使用者端訪問Hahow網站 => 伺服器端回傳空的HTML(無資料) => 使用者端透過JavaScript發送Ajax請求 => 伺服器端回傳資料,JavaScript用此資料渲染畫面
首先先在Hahow網站找到要爬取的課程資料 => 點擊右鍵找到開發者工具 => Network => Fetch/XHR => 開始逐一尋找API => Preview => data => courseData => products...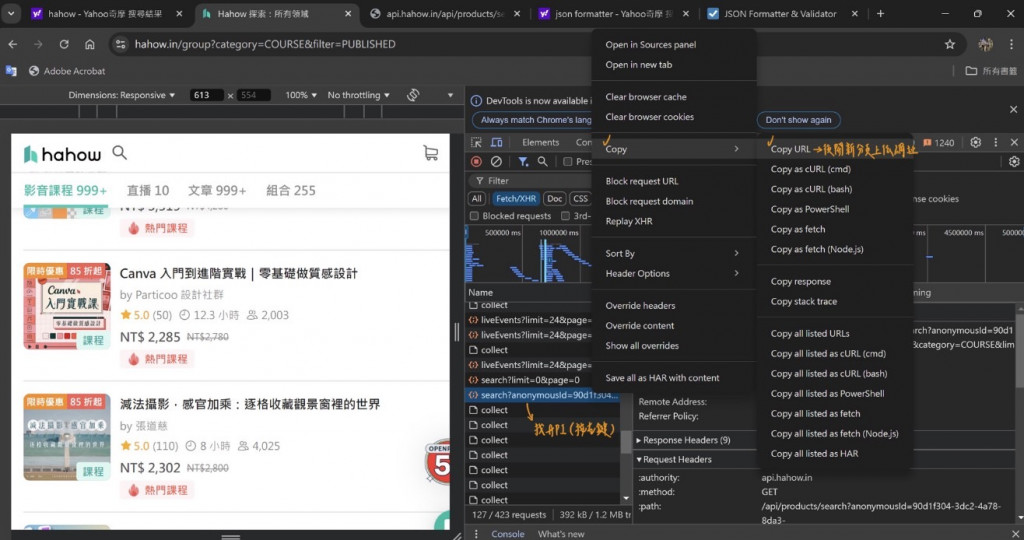
開新分頁,貼上複製的網址會跑出以下亂碼,後複製亂碼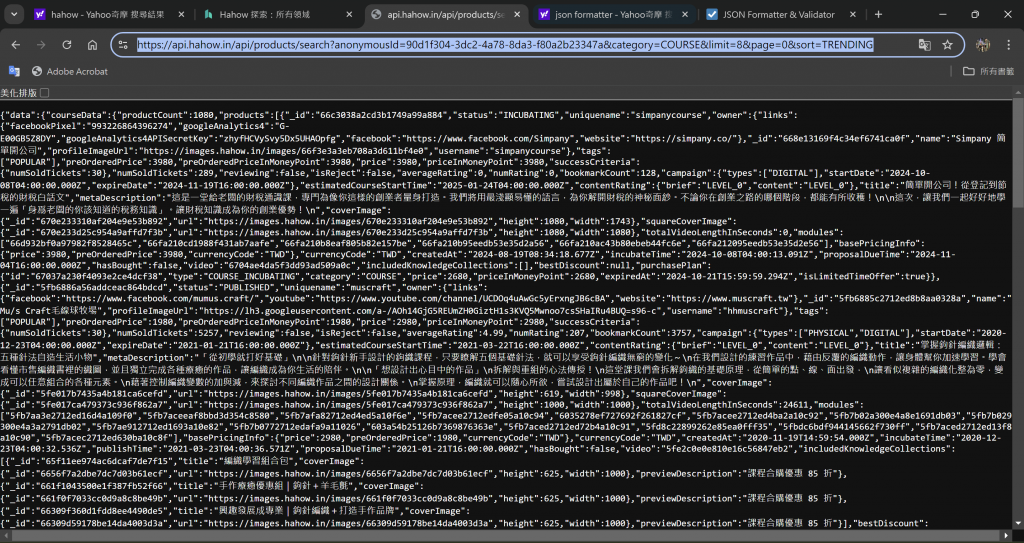
在新分頁查詢"JSON Formatter"後把複製後的亂碼貼上並點擊Process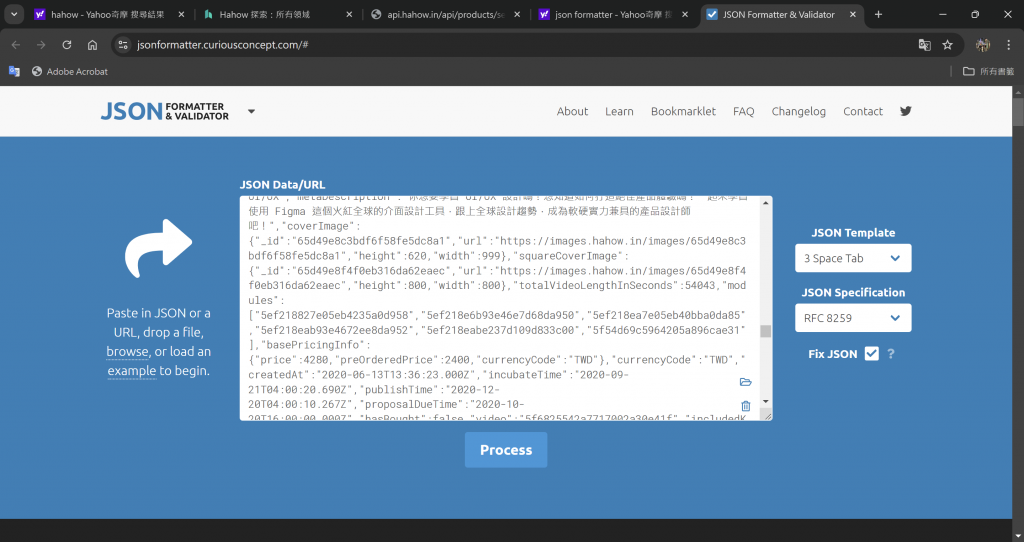
後會整理出以下畫面,可以點選全螢幕觀看整個JSON檔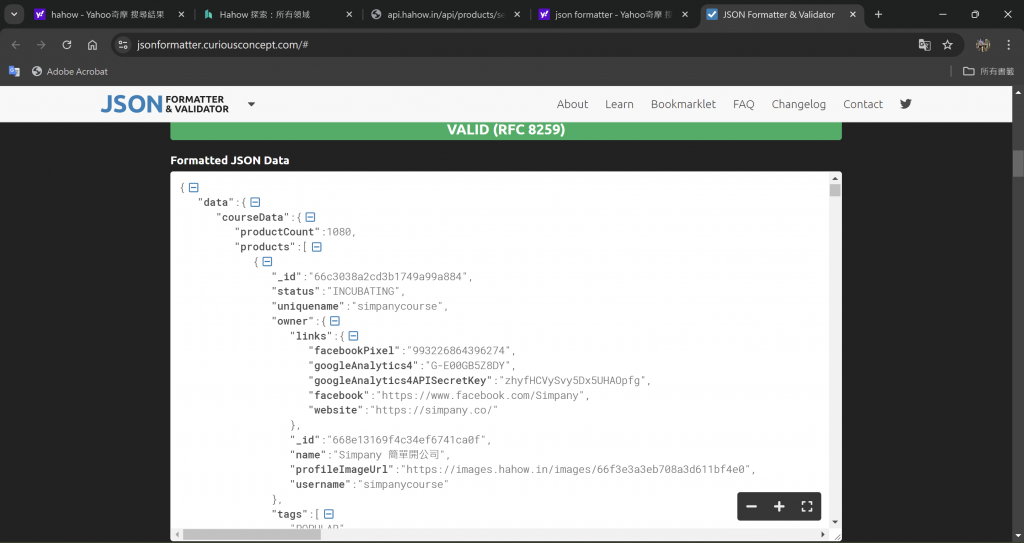
接下來是在pycharm中撰寫程式碼爬取網頁資料,程式碼如下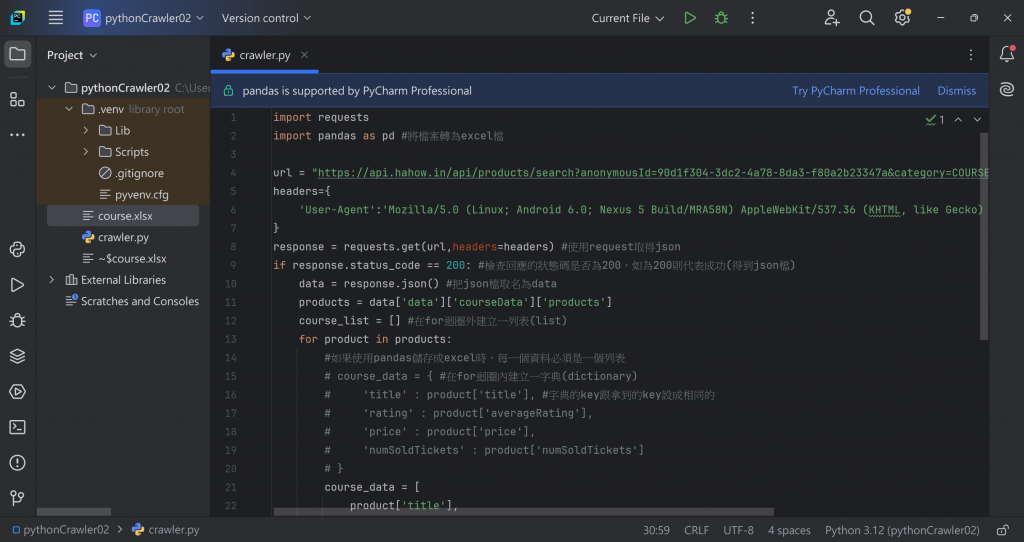
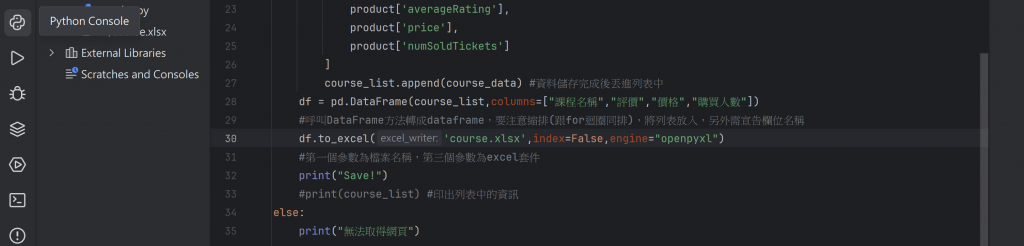
執行結果如圖(Excel檔)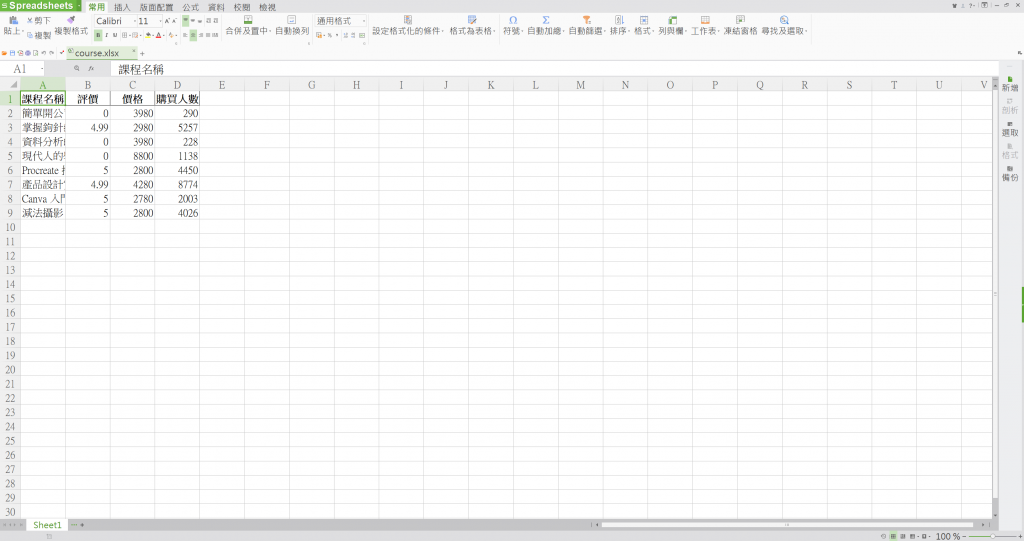
以上是我今天的分享,明天是挑戰的第30天!會分享Yahoo電影爬蟲以及這30天的心得,謝謝大家!
參考網址:https://www.youtube.com/watch?v=1PHp1prsxIM&list=LL&index=5

 iThome鐵人賽
iThome鐵人賽